| CPC G06N 3/082 (2013.01) [G06N 3/04 (2013.01)] | 20 Claims |
|
1. A method implemented by a hierarchical hardware, the method comprising:
receiving an input weight pattern of a neural network model from a computing device, and storing the input weight pattern into a weight memory of the hierarchical hardware;
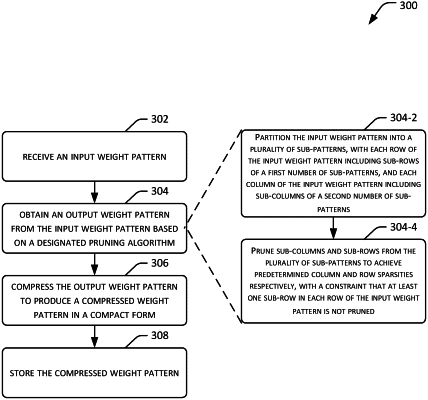
obtaining an output weight pattern configured to facilitate parallel computations from the input weight pattern based on a block-wise row and column pruning method, the block-wise row and column pruning method comprising:
partitioning the input weight pattern into a mesh network of sub-patterns, each row of the input weight pattern comprising sub-rows of a first number of sub-patterns, and each column of the input weight pattern comprising sub-columns of a second number of sub-patterns;
sending each sub-pattern of the sub-patterns from the weight memory to a respective sparse group compute engine (SGCE) of a plurality of sparse group compute engines of the hierarchical hardware, the weight memory being shared and accessible by the plurality of sparse group compute engines;
pruning, by the respective SGCE, respective one or more sub-columns from each sub-pattern to achieve a predetermined column sparsity; and
pruning, by the respective SGCE, respective one or more sub-rows from each sub-pattern to achieve a predetermined row sparsity under a constraint that, for each row of the input weight pattern, at least one sub-row of a sub-pattern in a respective row of the input weight pattern is not pruned; and
sending the output weight pattern to the computing device.
|