| CPC G06F 16/2471 (2019.01) [G06F 16/215 (2019.01); G06F 16/2465 (2019.01); G06F 16/252 (2019.01); G06F 16/256 (2019.01); G06F 16/258 (2019.01); G06N 5/04 (2013.01)] | 20 Claims |
|
1. A method comprising:
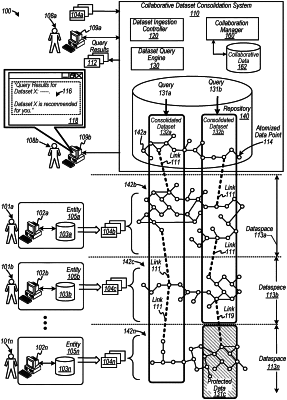
formatting a dataset to form a first atomized dataset including graph-based data associated with metadata including attributes of the dataset, the first atomized dataset being a first version;
forming a second atomized dataset including the first atomized dataset, the second atomized dataset including changed data as a second version from the first version;
receiving data representing a query;
re-writing the query to generate one or more sub-queries configured to access to the second version of the dataset including at least a portion of data stored in at least one of a different data repositories to perform a federated query;
classifying query portions of the one or more sub-queries to identify a classification type for a query portion;
applying the one or more sub-queries to the different data repositories; and
retrieving data responsive to the data representing the query.
|