| CPC G06F 16/2468 (2019.01) [G06F 16/22 (2019.01); G06F 16/285 (2019.01); G06V 10/761 (2022.01); G06V 20/54 (2022.01)] | 20 Claims |
|
1. A method comprising:
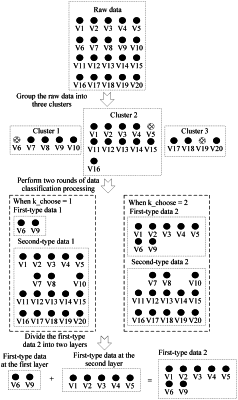
determining a first retrieval range in first-type data of N pieces of data stored in a database;
grouping the N pieces into M clusters, wherein M≥2, wherein each of the N pieces corresponds to one of the M clusters, wherein each of the M clusters has one central point, wherein each of the N pieces has a high similarity to a central point of a cluster to which each of the N pieces belong, and wherein cluster indexes uniquely identify the M clusters;
retrieving to-be-retrieved data in the first retrieval range to obtain a first retrieval result, wherein data in the first retrieval range is a subset of the first-type data;
retrieving the to-be-retrieved data from second-type data of the N pieces to obtain a second retrieval result, wherein the second-type data are at edge points of the M clusters; and
determining a final retrieval result of the to-be-retrieved data from the first retrieval result and the second retrieval result.
|