| CPC H04S 7/305 (2013.01) [G06N 3/04 (2013.01); G06N 3/08 (2013.01); H04S 7/307 (2013.01); H04S 2400/11 (2013.01)] | 20 Claims |
|
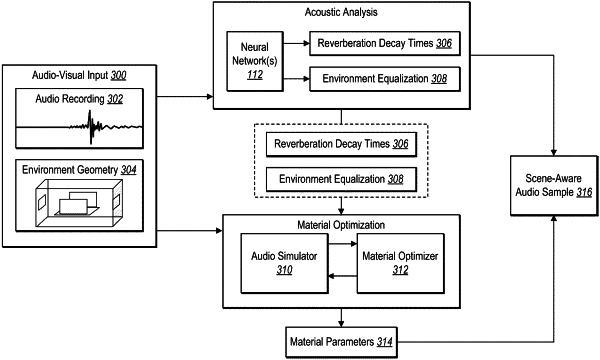
1. A computer-implemented method comprising:
determining, by at least one processor and based on an audio recording within an environment, a first energy curve by utilizing an audio simulation model to estimate sound paths within the environment by simulating paths of a plurality of audio rays via ray tracing according to an environment geometry of the environment and a reverberation decay time of the environment within a three-dimensional virtual representation generated for the environment;
modifying, by the at least one processor, material parameters of materials of surfaces within the three-dimensional virtual representation of the environment based on a difference between the first energy curve and a second energy curve corresponding to the reverberation decay time of the environment; and
generating, by the at least one processor, an audio sample based on the environment geometry, the material parameters, and an environment equalization of the environment.
|