| CPC G06V 20/46 (2022.01) [G06F 18/25 (2023.01); G06N 3/08 (2013.01); G06T 11/203 (2013.01); G06V 20/41 (2022.01); G10L 25/57 (2013.01)] | 20 Claims |
|
1. A computer-implemented method comprising:
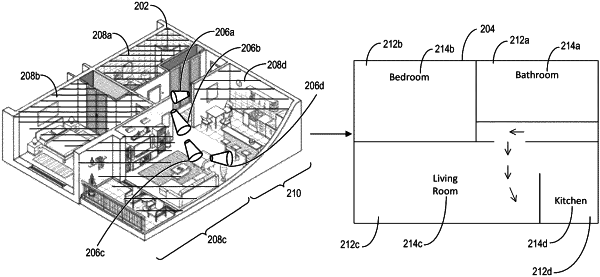
receiving a digital video depicting a viewed portion of a three-dimensional space, wherein the three-dimensional space comprises the viewed portion and an unviewed portion;
extracting visual features and audio features from a plurality of frame-audio sample pairs of the digital video by:
generating a visual feature encoding based on the visual features;
generating an audio feature encoding based on the audio features; and
generating an aligned visual feature encoding and an aligned audio feature encoding by projecting the visual feature encoding and the audio feature encoding to a two-dimensional feature grid;
generating a floorplan prediction utilizing a trained audio-visual floorplan reconstruction machine learning model from the aligned visual feature encoding and the aligned audio feature encoding generated from the plurality of frame-audio sample pairs; and
generating a two-dimensional floorplan of the viewed portion and the unviewed portion of the three-dimensional space from the floorplan prediction.
|