| CPC G06F 40/216 (2020.01) [G06F 16/24578 (2019.01); G06F 16/538 (2019.01); G06F 16/56 (2019.01); G06F 16/5854 (2019.01); G06F 18/213 (2023.01); G06F 18/214 (2023.01); G06F 18/22 (2023.01); G06F 40/30 (2020.01); G06N 3/08 (2013.01); G06V 10/75 (2022.01); G06V 30/19147 (2022.01); G06V 30/274 (2022.01)] | 20 Claims |
|
1. A method in which one or more processing devices perform operations comprising:
receiving, by a joint embedding model trained to generate an image result, a search query comprising a text input, wherein the joint embedding model is trained by:
accessing training data comprising a set of images and a set of textual information;
encoding the set of images into image feature vectors based on spatial features associated with each image;
encoding the set of textual information into textual feature vectors based on semantic information associated with each textual information;
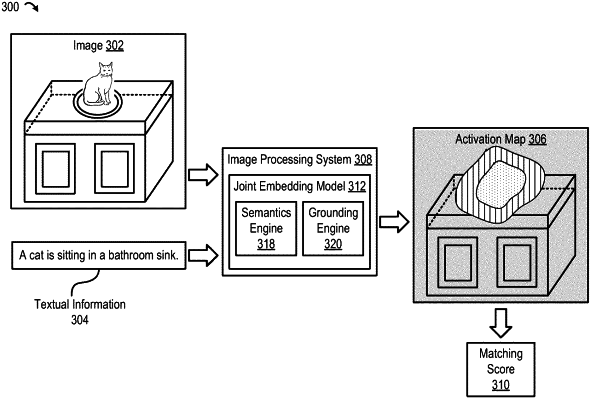
determining matches between the image feature vectors associated with the set of images and the textual feature vectors associated with the set of textual information, wherein determining the matches comprises at least determining objects in the image that are associated with the textual information;
generating a set of image-text pairs for the set of images based on the matches;
generating a visual grounding dataset for the set of images based on spatial information associated with each textual information and the spatial features associated with each image; and
generating activation maps comprising, for each image of the set of images, an activation map comprising textual feature vectors associated with regions in the image that are indicated by the visual grounding dataset;
generating, based on the activation maps, a set of visual-semantic joint embeddings for the set of images by grounding the set of image-text pairs using the visual grounding dataset; and
generating, for display, an image result using the joint embedding model by retrieving the image result based on the text input.
|