| CPC G06F 3/067 (2013.01) [G06F 3/0614 (2013.01); G06F 3/0644 (2013.01); G06F 3/0655 (2013.01); G06F 3/0683 (2013.01); G06F 11/102 (2013.01); H03M 13/1515 (2013.01)] | 20 Claims |
|
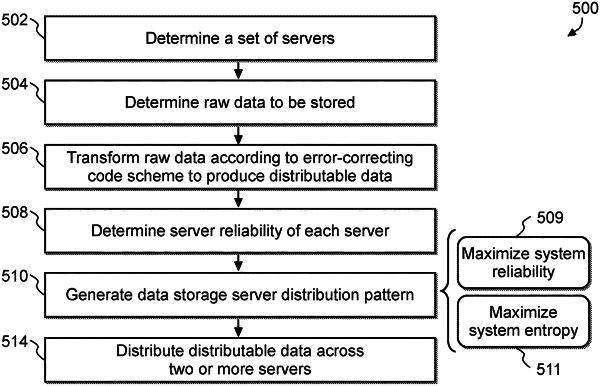
1. A computer-implemented method comprising:
transforming, with at least one processor, raw data according to an error-correcting code scheme to produce distributable data;
generating, with at least one processor, a data storage server distribution pattern for storing the distributable data across a subset of at least two servers from a set of available servers, wherein the data storage server distribution pattern comprises a partitioning of the distributable data such that no one server of the subset of at least two servers stores an entirety of the distributable data, and wherein generating the data storage server distribution pattern is based on maximizing a value of a combination of a system reliability and a system entropy by iteratively:
determining the system reliability based on permuting at least one error vector over a plurality of different partitions of the distributable data across the set of available servers, wherein each partition of the plurality of different partitions comprises a different allocation of bits to each server of the at least two servers of the distributable data, and wherein each error vector of the at least one error vector comprises an allocation of bit errors to each server of the at least two servers;
determining the system entropy based on a cumulated information entropy of each server of the set of available servers; and
determining the value of the combination of the system reliability and the system entropy; and
storing, with at least one processor, the distributable data across the subset of at least two servers according to the data storage server distribution pattern.
|