| CPC G06F 18/2185 (2023.01) [G06F 18/213 (2023.01); G06F 18/2148 (2023.01); G06T 19/20 (2013.01); G06V 10/242 (2022.01); G06V 20/64 (2022.01); G06T 2207/10024 (2013.01); G06T 2207/20084 (2013.01); G06T 2210/12 (2013.01); G06T 2219/2021 (2013.01)] | 20 Claims |
|
1. A system comprising:
a processor; and
a memory in communication with the processor and having machine-readable instructions that, when executed by the processor, cause the processor to:
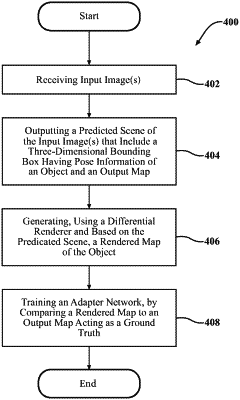
output, using a neural network that utilizes an input image that includes an object, a predicted scene that includes a three-dimensional bounding box having pose information of the object, wherein the neural network generates, in an intermediate operation, an output map indicating at least one of a shape of the object and a surface normal of the object,
generate, using a differentiable renderer and based on the predicted scene, a rendered map of the object, the rendered map including at least one of a rendered shape of the object and a rendered surface normal of the object, and
train an adapter network, which adapts the predicted scene to adjust for a deformation of the input image, by comparing the rendered map to the output map, wherein the output map is a ground truth.
|