| CPC G06F 16/313 (2019.01) [G06F 16/35 (2019.01); G06F 16/951 (2019.01); G06F 18/2411 (2023.01); G06N 20/10 (2019.01)] | 19 Claims |
|
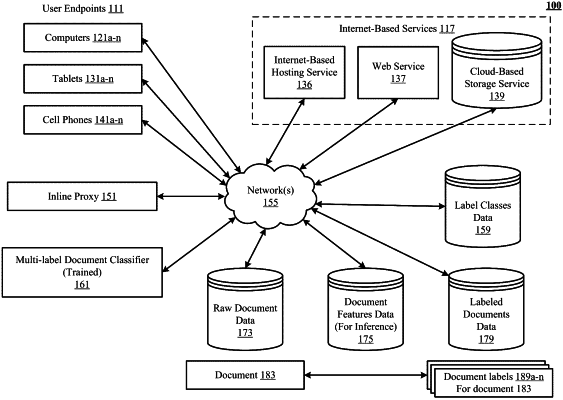
1. A system, comprising:
a multi-label document classifier, comprising:
a trained multi-label support vector machine (SVM) running a one-vs-the-rest classifier, wherein the trained multi-label SVM running the one-vs-the-rest classifier is trained to label input documents with one or more labels of a plurality of labels comprising at least fifty (50) labels, and the trained multi-label SVM is configured with trained parameters that are learned from training the trained multi-label SVM running the one-vs-the-rest classifier on:
document features of training documents each belonging to one or more of the plurality of labels, and
hyperplane determinations on labels in the plurality of labels, wherein the trained parameters include distributions of distances between the at least fifty labels and the hyperplanes, and the trained parameters are stored on a memory of the multi-label document classifier for use in applying the trained multi-label SVM running the one-vs-the-rest classifier;
a feature generator that creates the document features representing features of words in the input documents and the training documents; and
a harvester that:
harvests labels of the plurality of labels based on distances between the hyperplanes for the plurality of labels and the document features determined based on applying the trained multi-label SVM to the input documents, and
assigns the harvested labels to the input documents.
|