| CPC G06F 16/16 (2019.01) [G06N 5/04 (2013.01); G06N 20/00 (2019.01)] | 14 Claims |
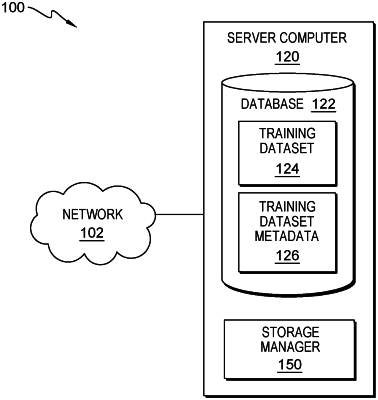
|
1. A computer-implemented method comprising:
determining, by one or more computer processors, a storage strategy for each chunked data block in a training dataset based on a respective computed score and a series of score thresholds, wherein the storage strategy comprises RAID strategies that include striping, mirroring, parity, and double parity, wherein the computed score is computed by:
responsive to an identified machine learning task associated with the training dataset, computing, by one or more computer processors, an aggregated information gain value and an aggregated heterogeneity value for each chunked data block;
computing, by one or more computer processors, the score for each chunked data block based on a product of respective computed information gain values and respective computed heterogeneity values; and
distributing, by one or more computer processors, each data block in the training dataset according to the respective determined storage strategy.
|