| CPC G10L 25/51 (2013.01) [G06N 3/045 (2023.01); G06N 3/08 (2013.01); G10L 25/21 (2013.01); G10L 25/30 (2013.01); G10L 15/08 (2013.01); G10L 15/22 (2013.01); G10L 2015/088 (2013.01); G10L 2015/223 (2013.01)] | 20 Claims |
|
1. A computer-implemented method comprising:
receiving, by a device associated with a user profile, first audio data including a plurality of audio frames;
determining, using first audio frames of the plurality of audio frames, first feature data representing log Mel-filterbank energy features;
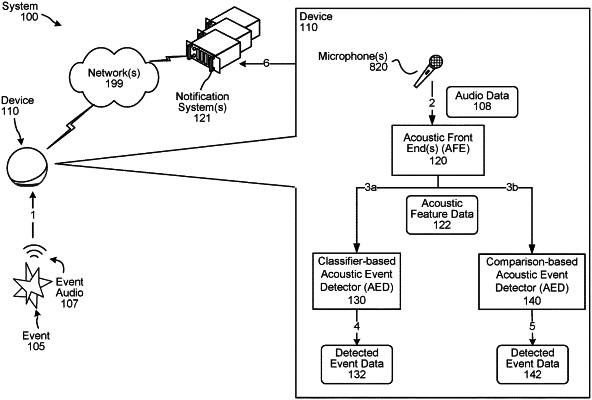
processing the first feature data using a first convolutional recurrent neural network (CRNN) to determine first encoded representation data, the first CRNN configured as an encoder associated with a first acoustic event detector to detect an acoustic event from a predetermined set of acoustic events;
processing the first feature data using a second CRNN to determine second encoded representation data, the second CRNN configured as an encoder associated with a second acoustic event detector different from the first acoustic event detector, the second acoustic event detector configured to detect an acoustic event from a custom set of acoustic events associated with the user profile;
determining, using the first encoded representation data and the first acoustic event detector, a likelihood that a first acoustic event from the predetermined set of acoustic events is represented in the first audio frames;
determining, using the second encoded representation data and the second acoustic event detector, comparison data representing that a second acoustic event from the custom set of acoustic events is represented in the first audio frames; and
determining, based at least in part on the likelihood and the comparison data, output data indicating that at least one of the first acoustic event or the second acoustic event occurred.
|