| CPC G10L 13/047 (2013.01) [A63F 13/215 (2014.09); A63F 13/54 (2014.09); G10L 13/033 (2013.01); G10L 21/007 (2013.01)] | 18 Claims |
|
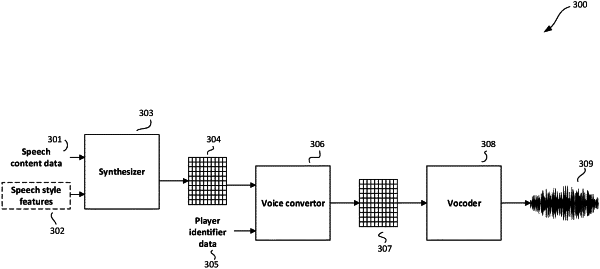
1. A computer-implemented method of generating speech audio in a video game using a voice convertor that has been trained to convert acoustic features for a source speaker into acoustic features for a player of the video game, the method comprising:
inputting, into a synthesizer module, input data representing speech content;
generating, as output of the synthesizer module, source acoustic features for the speech content in the voice of the source speaker;
inputting, into an acoustic feature encoder of the voice convertor, (i) a target speaker embedding associated with the player of the video game, wherein the target speaker embedding is a learned representation of the voice of the player, and (ii) the source acoustic features;
generating, as output of the acoustic feature encoder, one or more acoustic feature encodings, wherein generating the one or more acoustic feature encodings comprises generating an acoustic feature encoding for each input time step of a plurality of input time steps of the source acoustic features, wherein the acoustic feature encoding for each input time step comprises a combination of the target speaker embedding for the player and an encoding of the source acoustic features for the input time step;
inputting, into an acoustic feature decoder of the voice convertor, the one or more acoustic feature encodings;
generating target acoustic features, comprising decoding the one or more acoustic feature encodings using the acoustic feature decoder, wherein the target acoustic features comprise acoustic features for the speech content in the voice of the player, wherein decoding the one or more acoustic feature encodings comprises, for each output time step of a plurality of output time steps:
receiving the acoustic feature encoding for each input time step,
generating, by an attention mechanism, an attention weight for each acoustic feature encoding,
generating, by the attention mechanism, a context vector for the output time step by averaging each acoustic feature encoding using the respective attention weight, and
processing, by the acoustic feature decoder, the context vector of the output time step to generate target acoustic features for the output time step; and
processing the target acoustic features with one or more modules, the one or more modules comprising a vocoder configured to generate speech audio in the voice of the player.
|