| CPC G06V 40/173 (2022.01) [G06F 18/2178 (2023.01); G06F 18/23 (2023.01); G06V 20/40 (2022.01); G06V 40/179 (2022.01)] | 20 Claims |
|
1. A method, comprising:
identifying, by at least one processor of a first device, video frames of a television show having multiple seasons, the video frames including representations of unidentified actors;
identifying, using a convolutional neural network, faces represented by the video frames;
generating, by the at least one processor, based on a first episode of the television show, a first cluster of first faces of the faces;
generating, by the at least one processor, based on a second episode of the television show, a second cluster of second faces of the faces;
generating, by the at least one processor, based on a third episode of the television show, a third cluster of third faces of the faces;
determining, by the at least one processor, that a first cosine similarity between the first faces and the second faces exceeds a similarity threshold;
determining, by the at least one processor, that a second cosine similarity between the first faces and the third faces fails to exceed the similarity threshold;
selecting, by the at least one processor, based on the second cosine similarity, a first face to represent the first faces and the third faces;
selecting, by the at least one processor, based on the first cosine similarity, a second face to represent the second faces;
determining, by the at least one processor, a first score associated with the first episode, the first score indicative of a first number of faces to label using actor names, the first number of faces included in the first episode;
determining, by the at least one processor, a second score associated with the second episode, the second score indicative of a second number of faces to label using actor names, the second number of faces included in the second episode, the first score less than the second score;
selecting, by the at least one processor, based on a comparison of the first score to the second score, the first episode for face labeling;
sending, by the at least one processor, the first episode and the first face to a human operator;
receiving, by the at least one processor, from the human operator, a first face label for the first face, the first face label indicative of an actor's name;
generating, by the at least one processor, based on a comparison of the first face to a third face included in a fourth episode of the television show, a second face label for the third face, the second face label indicative of the actor's name;
sending, by the at least one processor, the third face and the second face label to the human operator;
receiving, by the at least one processor, from the human operator, a verification of the second face label; and
sending, by the at least one processor, the first face label and the second face label to a second device for presentation with the video frames.
|
|
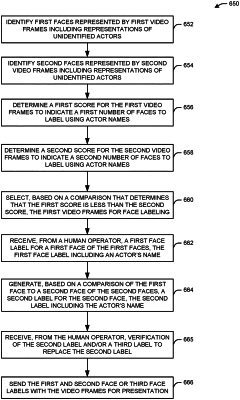
5. A method, comprising:
identifying, by at least one processor of a first device, first faces represented by first video frames of video frames, the video frames including representations of unidentified actors, the first faces comprising a first face;
identifying, by the at least one processor, second faces represented by second video frames of the video frames, the second faces comprising a second face;
determining, by the at least one processor, a first score associated with the first video frames, the first score indicative of a first number of faces to label using actor names, the first number of faces represented by the first video frames;
determining, by the at least one processor, a second score associated with the second video frames, the second score indicative of a second number of faces to label using actor names, the second number of faces represented by the second video frames, the first score less than the second score;
selecting, by the at least one processor, based on a comparison of the first score to the second score, the first video frames for face labeling;
receiving, by the at least one processor, from a human operator, a first face label for the first face, the first face label indicative of an actor's name;
generating, by the at least one processor, based on a comparison of the first face to the second face, a second face label for the second face, the second face label indicative of the actor's name; and
sending, by the at least one processor, the first face label and the second face label to a second device for presentation with the video frames.
|