| CPC G06T 19/006 (2013.01) [G06T 7/70 (2017.01); G06V 40/10 (2022.01); G10L 15/08 (2013.01); G10L 2015/088 (2013.01)] | 20 Claims |
|
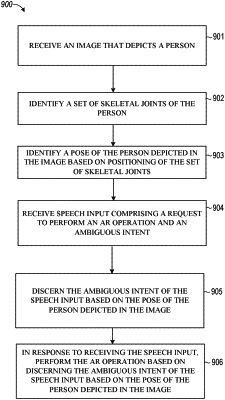
1. A method comprising:
receiving, by one or more processors, an image that depicts a person and one or more real-world objects comprising a body part;
identifying a set of skeletal joints of the person;
identifying a captured pose of the person depicted in the image based on positioning of the set of skeletal joints, the captured pose comprising the body part pointing along a particular direction;
receiving speech input comprising a request to perform an augmented reality (AR) operation, the speech input comprising an ambiguous intent;
discerning the ambiguous intent of the speech input based on the captured pose of the person depicted in the image;
identifying an object, depicted in the image, that intersects a line extending from the body part along the particular direction;
determining that the ambiguous intent of the speech input refers to the identified object based on the identified object intersecting the line extending from the body part; and
performing the AR operation based on determining that the ambiguous intent refers to the one or more real-world objects depicted in the image.
|