| US 11,790,411 B1 | ||
| Complaint classification in customer communications using machine learning models | ||
| Thomas Mann, Charlotte, NC (US); Michael W. Soistman, Charlotte, NC (US); Nathan R Parrish, Chaska, MN (US); Noel P. Volin, Hudson, WI (US); Raja Ranganathan, Cary, NC (US); Dane Arnesen, Saint Louis Park, MN (US); Shawn Bocketti, San Francisco, CA (US); Kevin Portis, San Francisco, CA (US); and Josh Engebretson, Charlotte, NC (US) | ||
| Assigned to Wells Fargo Bank, N.A., San Francisco, CA (US) | ||
| Filed by Wells Fargo Bank, N.A., San Francisco, CA (US) | ||
| Filed on Feb. 4, 2020, as Appl. No. 16/781,620. | ||
| Claims priority of provisional application 62/941,950, filed on Nov. 29, 2019. | ||
| Int. Cl. G06F 40/284 (2020.01); G06N 20/00 (2019.01); G06Q 30/02 (2023.01); G06Q 30/00 (2023.01); G10L 15/22 (2006.01); G10L 15/26 (2006.01); G06Q 30/016 (2023.01); G06Q 30/01 (2023.01) | ||
| CPC G06Q 30/0281 (2013.01) [G06F 40/284 (2020.01); G06N 20/00 (2019.01); G06Q 30/01 (2013.01); G06Q 30/016 (2013.01); G10L 15/26 (2013.01)] | 20 Claims |
|
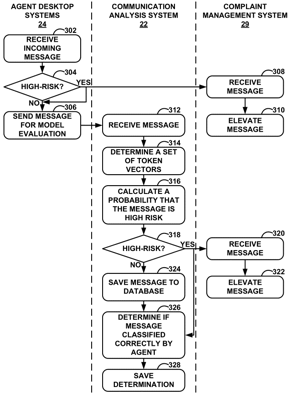
1. A computing system comprising:
a memory; and one or more processors in communication with the memory and configured to:
receive data indicative of a message from a user device, wherein the data indicative of the message comprises a string of characters;
receive, from an agent device, a risk classification corresponding to the message, wherein the risk classification:
classifies the message as a first risk level indicating that the message is to be elevated; or
classifies the message as a second risk level indicating that the message is not to be elevated, wherein the first risk level is greater than the second risk level;
identify, based on the string of characters, a set of token vectors from a plurality of token vectors generated based on a set of training data;
determine, using a machine learning model and based on the set of token vectors, a probability that a risk level associated with the message is the first risk level; and
determine whether the risk classification from the agent device is correct based on the probability that the risk level associated with the message is the first risk level.
|