| CPC G06N 3/045 (2023.01) [G06N 3/08 (2013.01)] | 20 Claims |
|
1. A system comprising:
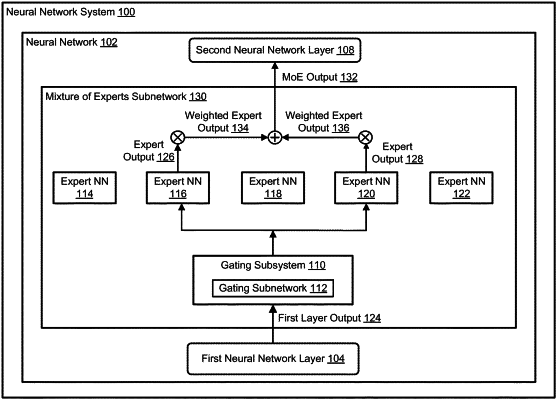
a main neural network implemented by one or more computers, the main neural network comprising a Mixture of Experts (MoE) subnetwork between a first neural network layer and a second neural network layer in the main neural network, wherein the MoE subnetwork comprises:
a plurality of expert neural networks, wherein each expert neural network is configured to process a first layer output generated by the first neural network layer in accordance with a respective set of expert parameters of the expert neural network to generate a respective expert output, and
a gating subsystem configured to:
generate a modified first layer output by applying a set of gating parameters to the first layer output,
add a final noise output to the modified first layer output to generate an initial gating output, wherein the final noise output is a vector having a plurality of elements, wherein each of the plurality of elements corresponds to a respective expert neural network of the plurality of expert neural networks, and wherein the number of elements in the vector is the same as the number of expert neural networks in the plurality of expert neural network, and
select, based on the initial gating output generated by adding the final noise output to the modified first layer output, one or more of the expert neural networks and determine a respective weight for each selected expert neural network,
provide the first layer output as input to each of the selected expert neural networks,
combine the expert outputs generated by the selected expert neural networks in accordance with the weights for the selected expert neural networks to generate an MoE output, and
provide the MoE output as input to the second neural network layer.
|