| CPC G06N 3/045 (2023.01) [G06N 3/08 (2013.01)] | 20 Claims |
|
1. A system for identifying one or more multimodal subevents within an event having spatially-related and temporally-related features, the system comprising:
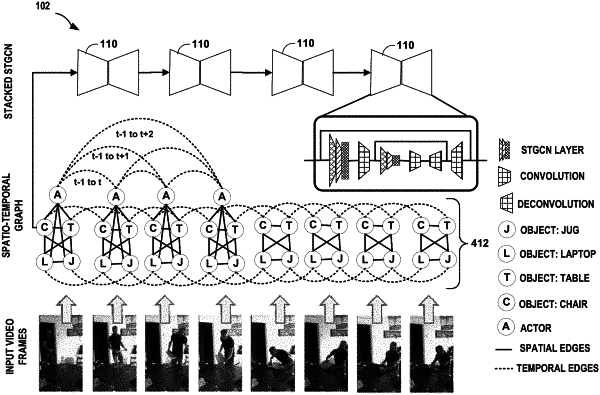
an input device configured to receive a Spatio-Temporal Graph (STG) comprising (1) a plurality of nodes, each node of the plurality of nodes having a feature descriptor that describes a feature present in the event, (2) a plurality of spatial edges, each spatial edge of the plurality of spatial edges describing a spatial relationship between two of the plurality of nodes, and (3) a plurality of temporal edges, each temporal edge of the plurality of temporal edges describing a temporal relationship between two of the plurality of nodes,
wherein the STG comprises at least one of: (1) variable-length descriptors for the feature descriptors or (2) temporal edges that span multiple time steps for the event;
a computation engine comprising processing circuitry for executing a machine learning system comprising one or more stacked Spatio-Temporal Graph Convolutional Networks (STGCNs), the one or more stacked STGCNs configured to process the STG to identify the one or more multimodal subevents for the event, wherein each stacked STGCN of the one or more stacked STGCNs comprises:
a plurality of STGCN layers comprising two or more of: a spatial graph convolution layer, a temporal graph convolution layer, or a non-linear convolution layer;
one or more convolutional layers configured to receive an output of the plurality of STGCN layers; and
one or more deconvolutional layers configured to receive an output of the one or more convolutional layers; and
an output device configured to output an indication of the one or more multimodal subevents.
|