| CPC G06F 16/285 (2019.01) [G06F 16/2255 (2019.01); G06F 16/2468 (2019.01); G06N 7/023 (2013.01)] | 19 Claims |
|
1. An order independent computer-implemented method of auditing a large-scale dataset for sensitive data, the method comprising:
receiving content from a real-time dataset of a live service environment;
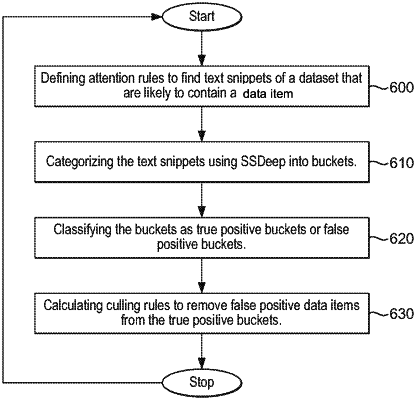
identifying data snippets of the real-time dataset using a set of one or more attention rules, wherein the one or more attention rules are opportunistic attention rules configured for maximising a recall rate, and each identified data snippet includes either a true positive data item or a false positive data item, wherein a true positive data item is a data item that matches one or more defined criteria associated with sensitive data, and a false positive data item is a data item that does not match the one or more defined criteria associated with sensitive data, wherein the recall rate indicates a portion of identified true positive data items that match the one or more defined criteria associated with sensitive data among true positive data items present in the received content;
categorizing the identified data snippets using fuzzy hashing by assigning them to buckets such that each bucket contains data snippets that are similar to one another according to a similarity measure defined by a fuzzy hashing algorithm for performing the fuzzy hashing;
classifying buckets containing data snippets having more than a threshold number of the true positive data items as true positive buckets and remaining buckets as false positive buckets;
calculating culling rules based on the true positive buckets and the false positive buckets, wherein the culling rules are configured to reduce a total number of false positive data items in the true positive buckets to increase a precision rate; and
using the culling rules to remove the false positive data items that do not meet the one or more defined criteria associated with sensitive data from the true positive buckets, to increase the precision rate that corresponds to a portion of true positive data items that meet the one or more defined criteria associated with sensitive data among data items in the true positive buckets.
|