| CPC G06F 16/24578 (2019.01) [G06F 16/93 (2019.01); G06F 40/268 (2020.01); G06F 40/279 (2020.01); G06N 3/08 (2013.01); G06N 20/00 (2019.01); G06F 2216/11 (2013.01); G06Q 10/10 (2013.01); G06Q 50/184 (2013.01)] | 22 Claims |
|
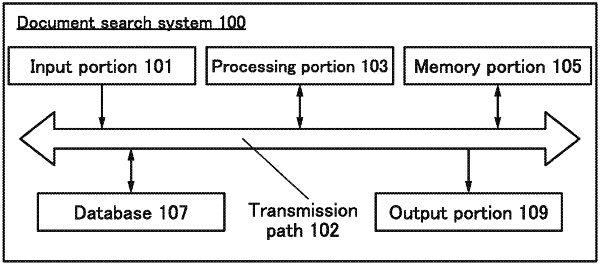
1. A document search system comprising:
a processing portion,
wherein the processing portion is configured to extract a keyword included in text data, to extract a related term of the keyword from words included in a plurality of pieces of first reference text analysis data, to give a weight to each of the keyword and the related term, to give a score to each of a plurality of pieces of second reference text analysis data on the basis of the weight, to rank the plurality of pieces of second reference text analysis data on the basis of the score to generate a ranking data, and to output the ranking data,
wherein the related term is extracted from the words included in the plurality of pieces of first reference text analysis data, on the basis of a similarity degree or a proximity of distance between distributed representation vectors of the words and a distributed representation vector of the keyword,
wherein the weight of the keyword is a value based on an inverse document frequency of the keyword in the plurality of pieces of first reference text analysis data or the plurality of pieces of second reference text analysis data,
wherein the weight of the related term is a product of the weight of the keyword by a value based on a similarity degree or a distance between a distributed representation vector of the related term and a distributed representation vector of the keyword, and
wherein the processing portion is configured to give a compiled weight to each of the keyword and the related term, to give a score to each of the plurality of pieces of second reference text analysis data on the basis of the compiled weight.
|