| CPC G06F 16/24568 (2019.01) [G06F 16/22 (2019.01); G06F 16/254 (2019.01)] | 20 Claims |
|
1. A method under control of one or more computing devices configured with specific computer-executable instructions to perform operations comprising:
obtaining, by a streaming data processor, a set of events;
identifying, by the streaming data processor, a first subset of events from the set of events as high importance events to be stored in an indexed data intake and query system configured to index events stored in the indexed data intake and query system and a second subset of events from the set of events as low importance events to be stored in a data storage system configured to store events without indexing, wherein the identifying is based at least in part on applying one or more criteria to a set of data field values extracted from individual events of the set of events, and wherein the data storage system is distinct from the indexed data intake and query system;
storing, in the indexed data intake and query system configured to index events stored in the indexed data intake and query system, the first subset of events from the set of events identified as high importance events to be stored in the indexed data intake and query system;
generating a storage prefix for each low importance event based at least in part on the set of data field values;
storing, in the data storage system distinct from the indexed data intake and query system and configured to store events without indexing, the second subset of events from the set of events identified as low importance events, wherein each low importance event is stored in the data storage system at a location based at least in part on the storage prefix for the low importance event;
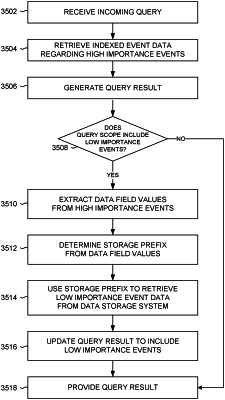
obtaining, by a query processor, a query for events;
identifying a high importance event stored in the indexed data intake and query system that is responsive to the query for events;
determining a storage prefix associated with the high importance event based at least in part on one or more data field values extracted from the high importance event;
obtaining, using the storage prefix determined to be associated with the high importance event identified as responsive to the query and stored in the indexed data intake and query system, one or more low importance events from a location in the data storage system distinct from the indexed data intake and query system and configured to store events without indexing, corresponding to the storage prefix associated with the high importance event; and
generating a set of search results including the high importance event and the one or more low importance events.
|