| CPC G06F 16/148 (2019.01) [G06F 16/144 (2019.01)] | 16 Claims |
|
1. A computer-implemented method comprising:
receiving at least one training document that includes a first plurality of tags, wherein the at least one training document corresponds to a document type, and wherein the first plurality of tags includes one or more first datum tags that each indicates a datum point of a first plurality of datum points of the at least one training document and one or more first relationship tags that each indicates a spatial relationship between the first plurality of datum points of the at least one training document;
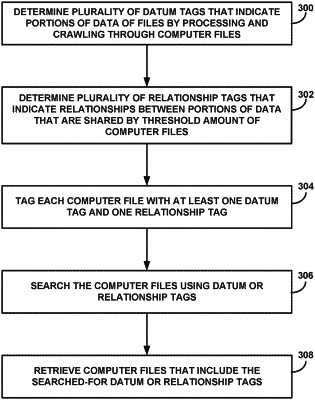
determining, for a plurality of computer files that include data stored in one or more unsearchable formats, a second plurality of tags by:
applying natural language processing to identify a second plurality of datum points included in each computer file of the plurality of computer files, wherein the natural language processing is applied to at least two different computer files of the plurality of computer files,
clustering the plurality of computer files and the at least one training document into one or more subsets of computer files having similar spatial relationships between the second plurality of datum points within the respective computer file of the plurality of computer files, wherein the at least two different computer files are clustered into a same subset of the one or more subsets of computer files, and wherein the same subset of the one or more subsets of computer files includes textual data defined by a predetermined category of data, and
generating the second plurality of tags based on the clustering of the plurality of computer files into the one or more subsets of computer files, wherein generating the second plurality of tags includes generating at least one textual datum tag that indicates different but synonymous terms or clauses of the textual data in the predetermined category of data included in the at least two different computer files,
wherein the second plurality of tags includes one or more second datum tags that each indicates a datum point of the second plurality of datum points of at least one computer file of the plurality of computer files and one or more second relationship tags that each indicates a spatial relationship between data the second plurality of datum points of the at least one computer file of the plurality of computer files, wherein each of the plurality of computer files corresponds to a textual document, and wherein the one or more second datum tags includes the at least one textual datum tag;
tagging each computer file of the plurality of computer files based on the determined second plurality of tags such that each computer file is associated with at least one of the second datum tags of the second plurality of tags and at least one of the second relationship tags of the second plurality of tags, wherein the at least two different computer files are tagged with the at least one textual datum tag;
searching the plurality of computer files for the at least one textual datum tag of the second plurality of tags; and
retrieving, in response to the searching, a subset of the plurality of computer files that contain the at least one textual datum tag of the second plurality of tags.
|