| CPC G06F 16/13 (2019.01) [G06F 16/27 (2019.01); G06F 16/285 (2019.01)] | 20 Claims |
|
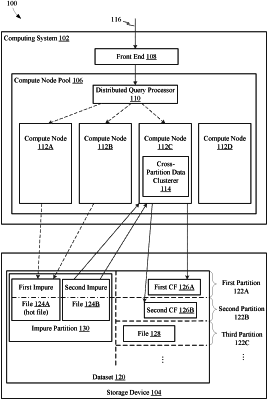
1. A system for improved access to rows of data, each data row associated with a partition of a plurality of partitions, the data rows distributed in one or more files, wherein a file including data rows associated with different partitions of the plurality of partitions is an impure file, the system comprising:
at least one processor;
a first compute node that includes first program code structured to cause the at least one processor to:
select a subset of impure files from a plurality of impure files; and
schedule a clustering task in a queue for sorting data rows of the subset of impure files; and
a second compute node that includes second program code structured to cause the at least one processor to, independent of the first compute node:
retrieve the clustering task from the queue;
execute the sorting of the data rows of the subset of the impure files according to a respective associated partition of each of the data rows;
generate a set of disjoint partition range files based on the sorting; and
transfer each file of the disjoint partition range files to a respective target pure partition.
|