| CPC H04L 63/0861 (2013.01) [G10L 15/1815 (2013.01); G10L 15/1822 (2013.01); G10L 17/06 (2013.01); G10L 17/22 (2013.01); H04L 63/0853 (2013.01)] | 20 Claims |
|
1. A system for bi-direction voice authentication comprising:
at least one processor; and
memory including instructions that, when executed by the at least one processor, cause the at least one processor to perform operations to:
receive an authentication request from a user;
determine that a device that transmitted the authentication request is located in a public place;
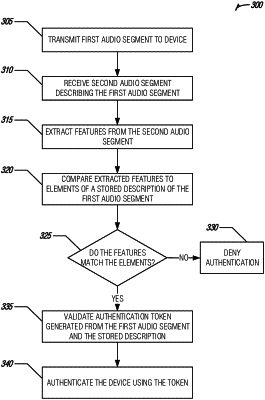
transmit an audio segment to the device with a request for confirmation of the audio segment and a request for a text-based response that includes a description of the audio segment from the user, the audio segment including audio content previously provided by the user;
receive the description of the audio segment from the device in the text-based response, wherein the description includes a unique sequence of words based on user-specific content of the audio segment;
compare the description to a profile description of the audio segment included in a profile stored for the user that includes the audio segment and the profile description, the profile description including a natural language description for the audio segment previously provided by the user;
upon receipt of the confirmation of the audio segment and a determination that the description matches the profile description, select an authentication token for the user;
transmit the authentication token to the device; and
authenticate requests for secure information using the authentication token for a duration of an interaction session between the user and the device.
|