| CPC G10H 1/368 (2013.01) [G10H 1/366 (2013.01); G11B 27/02 (2013.01); G11B 27/031 (2013.01); G11B 27/10 (2013.01); G11B 27/28 (2013.01); G11B 27/34 (2013.01); G10H 2210/331 (2013.01); G10H 2220/005 (2013.01); G10H 2220/011 (2013.01); G10H 2220/355 (2013.01); G10H 2230/015 (2013.01); G10H 2240/175 (2013.01); G10H 2240/251 (2013.01)] | 20 Claims |
|
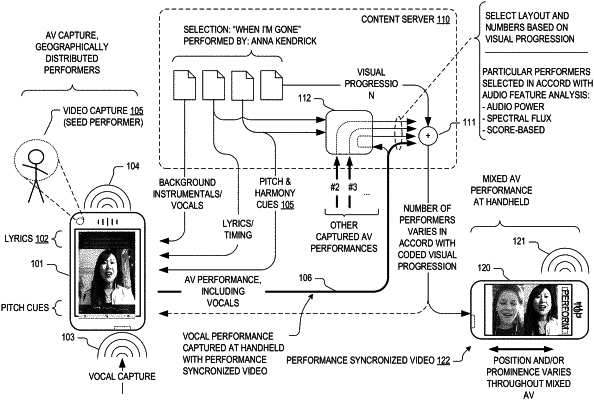
1. A method of preparing a coordinated audiovisual work from geographically distributed performer contributions, the method comprising:
based on a computer readable encoding of a visual progression that encodes a sequence of visual layouts, wherein the visual progression is generated from an encoding of a backing track, each visual layout of the sequence of visual layouts specifying an arrangement of one or more visual cells in which respective vocals and temporally synchronized videos of one or more performers are visually renderable, associating individual ones of one or more captured audiovisual performances corresponding to respective ones of the one or more performers, including respective encodings of performer vocals and temporally synchronized videos, to respective ones of the one or more visual cells; and
rendering the coordinated audiovisual work, in accordance with the visual progression and the associations, as an audio mix and coordinated visual presentation of the captured one or more audiovisual performances.
|