| CPC G06V 10/82 (2022.01) [G06T 5/00 (2013.01); G06V 10/809 (2022.01); G06V 30/19173 (2022.01); G06F 3/013 (2013.01); G06F 3/017 (2013.01); G06F 3/041 (2013.01)] | 20 Claims |
|
1. A tangible, non-transitory, computer-readable medium storing computer program instructions that when executed by one or more processors effectuate operations comprising:
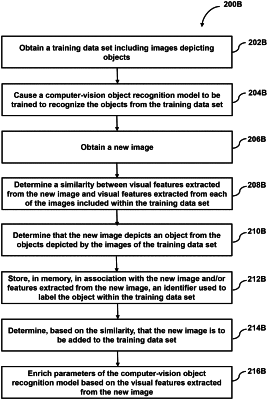
obtaining, with a computer system, a first training set to train a computer vision model, the first training set comprising images depicting objects and labels corresponding to object identifiers and indicating which object is depicted in respective labeled images;
training, with the computer system, the computer vision model to detect the objects in other images based on the first training set, wherein training the computer vision model comprises:
encoding depictions of objects in the first training set as vectors in a vector space of lower dimensionality than at least some images in the first training set, and
designating, based on the vectors, locations in the vector space as corresponding to object identifiers;
obtaining a first vector encoding a first depiction of a first object in a first query image;
determining similarity between the first depiction of the first object in the first query image and another object in an image of the first training set based on a first distance between the first vector and a second vector associated with the another object in the image of the first training set,
designating as a first object identifier associated with the first object in the first query image, an object identifier associated by the trained computer vision model with the another object in the image of the first training set;
determining, with the computer system, based on the first distance between the first location of the first vector in the vector space and the second location of the second vector in the vector space, to add the first image or data based on the first image to a second training set, wherein:
the second training set comprises both at least some of the images from the first training set and the first image,
the first image is absent from the first training set, and
the first image is labeled as depicting the first object in the second training set; and
training, with the computer system, the computer vision model with the second training set.
|