| CPC G06T 7/11 (2017.01) [G06N 3/08 (2013.01); G06T 7/174 (2017.01); G06T 7/74 (2017.01); G06T 2207/10024 (2013.01); G06T 2207/10028 (2013.01); G06T 2207/20081 (2013.01); G06T 2207/20084 (2013.01); G06T 2207/20221 (2013.01)] | 1 Claim |
|
1. A depth-aware method for mirror segmentation, comprising steps of:
step 1, constructing a new mirror segmentation dataset RGBD-mirror
constructing a mirror segmentation dataset with depth information; a dataset contains multiple groups of pictures, each group has an RGB mirror image, a corresponding depth image and a manually annotated mask image; mirrors appearing in dataset images are common in daily life, and the images cover different scenes, styles, positions, and numbers; randomly splitting the dataset into training set and testing set;
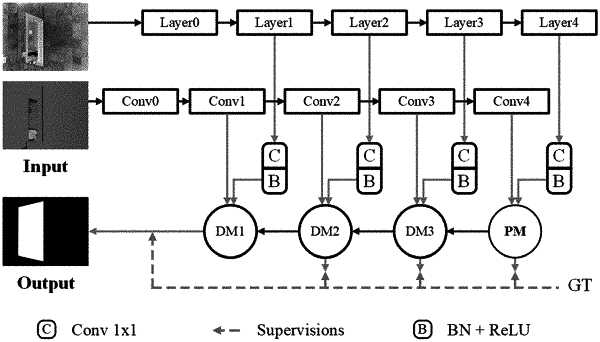
step 2, building PDNet
mirror segmentation network PDNet mainly consists of a multi-level feature extractor, a positioning module, and three delineating modules;
the multi-level feature extractor takes a RGB image and corresponding depth image as input, both of which come from the mirror segmentation dataset in step 1; realization of the multi-level feature extractor is based on ResNet-50 with feature extraction capabilities; taking as input the RGB and depth image pairs and first conducts channel reduction convolution for computational efficiency and then feeds features into the positioning module and three continuous delineating modules;
given RGB and depth features, the positioning module estimates initial mirror location, as well as corresponding features for guiding subsequent delineating modules, based on global and local discontinuity and correlation cues in both RGB and depth; the positioning module consists of two subbranches: a discontinuity perception branch and a correlation perception branch;
the discontinuity perception branch extracts and fuses discontinuity features for RGB domain (Dr), depth domain (Dd), and RGB+depth domain (Drd); each of these features is extracted by a common discontinuity block, and is element-wise addition of local and global discontinuity features, Dl and Dg, respectively, i.e. D=Dl⊕Dg; given a feature F, the local discontinuity feature Dl is the difference between a local region and its surroundings:
Dl=R(N(ƒl(F,Θl)−ƒs(F,Θs)))
where ƒl extracts features from a local area using a convolution with a kernel size of 3 and a dilation rate of 1, followed by a batch normalization (BN) and a ReLU activation function; ƒs extracts features from the surrounding using a convolution with kernel size of 5 and a dilation rate of 2, followed by BN and ReLU; while the local discontinuity feature captures the differences between local regions and their surroundings, under certain viewpoints, a reflected mirror image has little overlap with its surroundings; the global discontinuity feature represents this case:
Dg=R(N(ƒl(F,Θl)−ƒg(G(F),Θg)
where, G is a global average pooling, and ƒg is a 1×1 convolution followed by BN and ReLU; applying discontinuity block to RGB, depth, and RGB+depth, and fusing the resulting features Dr, Dd, and Drd to produce a final output of the discontinuity perception branch:
DDPB=R(N(ψ3×3([Dr,Dd,Drd])))
where, [⋅] denotes a concatenation operation over the channel dimension, and ψt×t represents the convolution with a kernel size of t;
the correlation perception branch models correlations inside and outside the mirror; the correlation perception branch is inspired by a non-local self-attention model augmented with a dynamic weighting to robustly fuse RGB and depth correlations, which adjusts the importance of an input domain during fusion based on its quality:
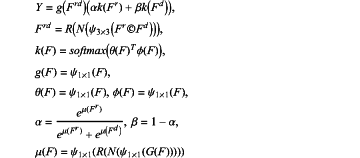 where, Fr and Fd are the input RGB and depth features, α and β are dynamic weights, © is a channel-wise concatenation operator; finally, to enhance fault tolerance, the positioning module uses a residual connection with a learnable scale parameter γ: CCPB=γY⊕Frd;
adding an output results of two branches DDPB and CCPB at a pixel level, and the result is a output of the positioning module;
given high-level mirror detection features, either from the positioning module or previous level's delineating module, the delineating module refines a mirror boundary; the core of the delineating module is a delineating block that takes advantage of local discontinuities in both RGB and depth to delineate the mirror boundaries; since such refinements should only occur in a region around the mirror, leveraging higher-level features from the previous module (either positioning module or delineating module) as a guide to narrow down potential refinement areas; given a feature F and corresponding high-level feature Fh, the delineating module computes a feature T as:
T=R(N(ƒl(F⊕Fhg,Θl)−ƒs(F⊕Fhg,Θs))),
Fhg=U2(R(N(ψ3×3(Fh))))
where U2 is a bilinear upscaling (by a factor 2); similar as the discontinuity block, the delineating module applies the delineating block to RGB domain, depth domain, and RGB+depth domain, and fuses the features to obtain a final output feature TDM as the below equation:
TDM=R(N(ψ3×3([Dr,Dd,Drd])))
step 3, training process
during training, an input of the multi-level feature extractor is the images in the training set, and the positioning module and three delineating modules take extracted results as input; then, the positioning module combines highest level RGB and depth features to estimate an initial mirror location, and the delineating module combines high-level mirror detection features, either from the positioning module or previous level's delineating module to refine the mirror boundary; to improve the training, the positioning module and three delineating modules are supervised by ground truth mirror masks annotated manually; computing a loss between the G and mirror segmentation map S predicted according to each of the features generated by the four modules as: S=ψ3×3(X), where X is an output feature from either the positioning module or delineating module:
L=wblbce(S,G)+wiliou(S,G)+weledge(S,G)
where lbce is a binary cross-entropy loss, liou is a map-level IoU loss, and ledge is a patch-level edge preservation loss; and wb=1, wi=1, we=10 are the corresponding weights for each of the three loss terms; a final loss function is then defined as:
Loverall=Lpm+2Ldm3+3Ldm2+4Ldm1
a function can guide PDNet to generate a more accurate mirror segmentation result based on the input RGB and corresponding depth image.
|