| CPC G06Q 30/0211 (2013.01) [G06Q 30/0205 (2013.01); G06Q 30/0226 (2013.01)] | 18 Claims |
|
1. A system comprising:
a communications interface;
a memory resource storing instructions; and
at least one processor coupled to the communications interface and to the memory, the at least one processor being configured to execute the instructions to:
adaptively train a machine learning model using training datasets associated with a first prior temporal interval, based on at least one of: a light gradient boosted model, a random forest or a gradient boosted decision tree process;
validate the machine learning model based on validation datasets associated with a second prior temporal interval that is distinct from the first prior temporal interval;
obtain a set of features of a set of users including one or more features of transaction of the set of users and one or more features of engagement data of the set of users;
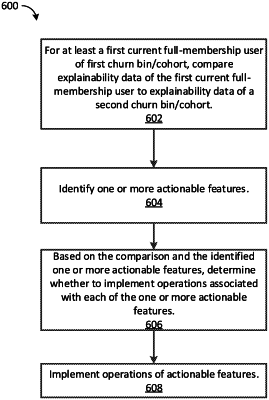
based on the set of features, implement a first set of operations including applying the trained and validated machine learning model to the set of features to generate output data including a plurality of churn scores, each churn score of the plurality of churn scores being associated with a particular user of the set of users and characterize a likelihood of a churn event of the corresponding user;
based on the output data and multiple churn cohorts, sort a user identifier of each of the set of users into one of the multiple churn cohorts, each of the multiple churn cohorts representing one of multiple predetermined ranges of churn scores;
for a first churn cohort of the multiple churn cohorts, implement a second set of operations that generate first explainability data associated with the first churn cohort, wherein
the first explainability data includes a distribution of values characterizing contributions of an actionable feature of all users sorted into the first churn cohort to the churn scores in the first churn cohort,
the distribution of values comprises: (a) a positive portion including values that positively contribute to the churn scores in the first churn cohort, (b) a negative portion including values that negatively contribute to the churn scores in the first churn cohort, and (c) an inflection point separating the positive portion and the negative portion;
compare the distribution of values in the first explainability data associated with all users sorted into the first churn cohort to a corresponding value in second explainability data associated with a single user sorted into a second churn cohort of the multiple churn cohorts, wherein
the first churn cohort represents a first range of churn scores,
the second churn cohort represents a second range of churn scores,
the second range of churn scores is a lower range than the first range of churn scores;
identify, based on the comparing, whether the corresponding value is within the negative portion or the positive portion of the distribution; and
determine, based on the identifying, whether to implement operations associated with the actionable feature for the single user.
|