| CPC G06N 3/088 (2013.01) [G06F 11/3664 (2013.01); G06F 11/3684 (2013.01); G06F 11/3688 (2013.01); G06F 11/3692 (2013.01)] | 24 Claims |
|
1. A computer-implemented method, comprising:
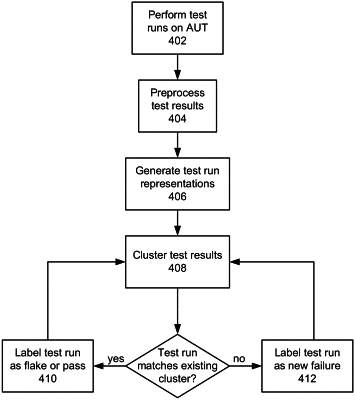
performing a plurality of training test runs for an application under test (AUT), each training, test run involving execution of test code against a corresponding instance of the AUT, each training test run resulting in corresponding training test results;
simplifying the training test results for each training test run by removing noisy information from the training test results;
generating a training test run representation implemented as a vector representation for each of the training test runs using the corresponding simplified training test results;
performing dimensionality reduction on the training test run representations implemented as vector representations;
clustering the training test run representations into a plurality of test run clusters;
identifying each of a subset of the test run clusters as representing training test runs exhibiting inconsistent failure behavior in which successive test runs using a same AUT and a same test code result in one or more passes and one or more fails;
performing a first test run for the AUT by executing the test code against a corresponding instance of the AUT, thereby generating first test results;
simplifying the first test results by removing noisy information from the first test results;
generating a first test run representation implemented as a vector representation using the simplified first test results;
determining that the first test run representation corresponds to a first one of the subset of test run clusters;
identifying one or more differences between the first test run representation and one or more previous test run representations by comparing respective vector representations implementing the first test run representation and the one or more previous test run representations;
quantifying the one or more differences;
translating the quantified one or more differences to a representation of how likely the first test run is reliable or unreliable; and
labeling the first test run with a reliability label indicating the representation of how likely the first test run is reliable or unreliable.
|