| CPC G06F 40/279 (2020.01) [G06F 40/30 (2020.01); G06N 5/022 (2013.01)] | 18 Claims |
|
1. A method, comprising:
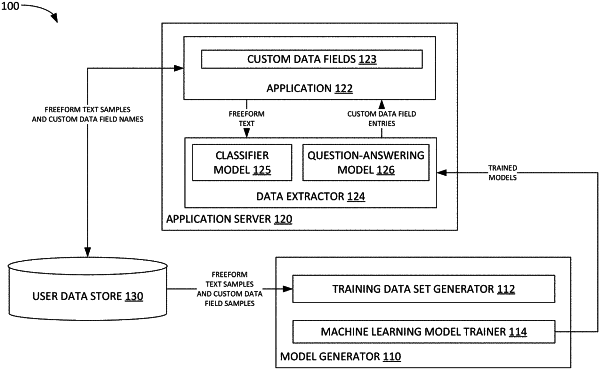
generating, via a natural language processing pipeline, a training data set from a data set of freeform text samples and field entries for a plurality of custom fields defined by users of a software application, each entry in the training data set including a mapping between a custom field name and relevant textual content in a freeform text sample in the data set;
training a first machine learning model based on the training data set to identify custom fields for which relevant data is included in any freeform text, wherein the custom fields comprise fields not included in a set of defined fields in the software applications, and wherein the first machine learning model comprises a classifier model configured to determine whether relevant text for a custom field exists in the freeform text sample; and
training a second machine learning model based on the training data set to extract content from the freeform text samples into one or more custom fields of the plurality of custom fields defined in the software application and identified by the first machine learning model as custom fields for which relevant data is included in the freeform text samples, wherein the second machine learning model comprises a question-answering model configured to identify the relevant text for the custom field.
|