| CPC G06F 16/9538 (2019.01) [G06F 16/958 (2019.01); G06N 20/00 (2019.01)] | 20 Claims |
|
1. A computer-implemented method comprising:
generating, by a server, a set of vectors representing n-gram values corresponding to a plurality of terms of a set of web documents;
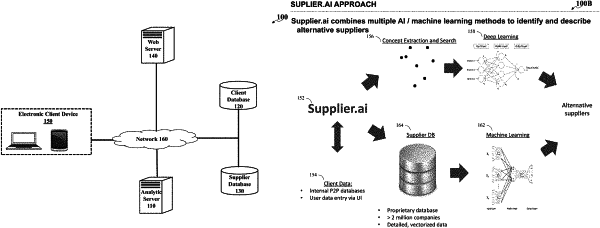
executing, by the server, a first artificial intelligence model configured to receive the set of vectors and to generate an importance score for each web document, the importance score indicating a likelihood that the web document corresponds to a supplier rather than a non-supplier;
executing, by the server, a second artificial intelligence model configured to:
receive a first subset of the set of vectors corresponding to a first subset of the set of web documents satisfying an importance value threshold and to generate a similarity score associated with each web document within the first subset of the set of web documents, the similarity score corresponding to a similarity between the plurality of search attribute inputs and the web document;
selecting, by the server, a second subset of the first subset of the set of web documents satisfying a similarity score threshold; and
presenting, by the server, for display on a graphical user interface, at least one web document within the second subset of the first subset of the set of web documents.
|