| CPC G06F 16/285 (2019.01) [G06F 16/2237 (2019.01); G06F 16/2264 (2019.01); G06F 16/93 (2019.01)] | 15 Claims |
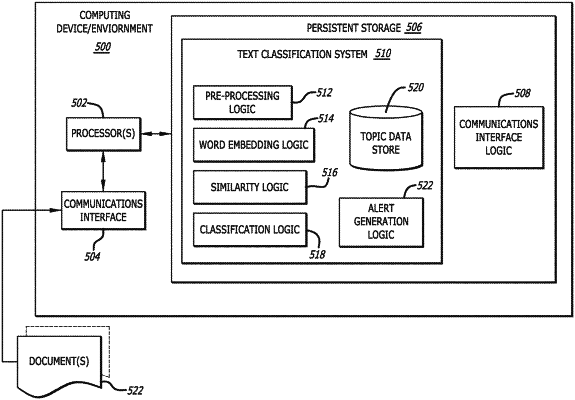
|
1. A computer-implemented method, comprising:
receiving a ticketing document to be classified, wherein the ticketing document includes a text portion;
performing pre-processing operations on the text portion of the ticketing document resulting in generation of a tokenized document;
performing first word embedding operations on the tokenized document including mapping each token of the tokenized document to a corresponding pre-generated vector resulting in generation of a vectorized document, wherein a first pre-generated vector mapped to a token of the tokenized document represents a semantic meaning of the token of the tokenized document, and wherein the mapping of each token of the tokenized document to the corresponding pre-generated vector is performed without use of machine learning techniques;
performing second word embedding operations on a set of tokenized topics, wherein each tokenized topic is a set of tokens comprising a set of related words, wherein the second word embedding operations include mapping each token of each tokenized topic of the set of tokenized topics to a corresponding pre-generated vector resulting in generation of a set of topic vectors, wherein a second pre-generated vector mapped to a token of the set of tokenized topics represents a semantic meaning of the token of the set of tokenized topics, and wherein the mapping of each token of each tokenized topic to the corresponding pre-generated vector is performed without use of the machine learning techniques;
performing text similarity operations on the vectorized document and each of the set of topic vectors without use of the machine learning techniques resulting in a set of similarity scores indicating a level of semantic similarity between the vectorized document and a topic vector, wherein a first similarity score indicates a level of similarity between the vectorized document and a first topic vector, and wherein each topic vector represents one of a predetermined set of topics; and
classifying the ticketing document into one of the predetermined set of topics based on the set of similarity scores.
|