| CPC G06F 16/285 (2019.01) [G06Q 30/0201 (2013.01)] | 11 Claims |
|
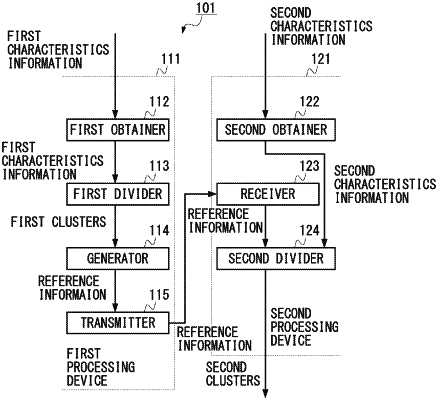
1. A processing system comprising a first processing device and a second processing device, wherein
(a) the first processing device
obtains first characteristics information indicating a characteristic of each of a plurality of users in a first environment,
divides the plurality of users into a plurality of first clusters according to the obtained first characteristics information of the plurality of users, wherein a first user of the plurality of users is allocated to a first cluster, among the plurality of first clusters, according to the obtained first characteristic information of the first user, and
transmits, to the second processing device, representation information, which indicates, with respect to the first user of the plurality of users, a degree of similarity between a centroid vector of the first cluster, to which the first user has been allocated, and the first characteristics information obtained for the first user, upon which the first user has been allocated to the first cluster; and
(b) the second processing device
obtains second characteristics information indicating a characteristic of each of the plurality of users in a second environment that is different from the first environment, and
divides the plurality of users into second clusters by using the transmitted representation information and the obtained second characteristics information for each of the plurality of users,
wherein the second processing device allocates the first user into a second cluster, among the second clusters, by using, as a feature vector for clustering, a result of concatenating or combining (i) the degree of similarity between the centroid vector of the first cluster, to which the first user has been allocated, and the first characteristics information obtained for the first user, upon which the first user has been allocated to the first cluster, and (ii) the second characteristics information obtained for the first user.
|