| CPC G06F 16/258 (2019.01) [G06F 16/113 (2019.01); G06F 16/211 (2019.01); G06F 16/215 (2019.01); G06F 16/2282 (2019.01); G06F 40/205 (2020.01)] | 7 Claims |
|
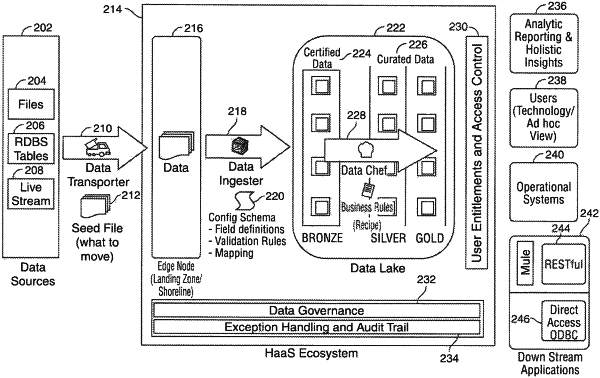
1. A system for standardizing data input, data output and data manipulation at a data lake, the system comprising:
a data transporter, executing on a processor coupled to a memory, said data transporter operable to:
receive a seed file, said seed file comprising a list of data elements and a data source location for each data element included in the list of data elements;
parse the seed file into a plurality of data elements and associated data source locations;
validate the seed file by validating that each data element, included in the plurality of data elements, is located in the data source location included in the plurality of data elements and associated data source locations;
retrieve the data elements from the plurality of data source locations; and
transfer the retrieved data elements from the data source locations to an edge node at a data lake;
a data ingester, operating on the processor coupled to the memory, said data ingester operable to:
receive a first schema configuration file for each of the data elements, said first schema configuration file comprising field definitions, validation rules and mappings;
label each of the data elements, located at the edge node at the data lake, based on the received first schema configuration file;
convert a format of each of the data elements, located at the edge node at the data lake, from a native format to a data lake accessible format;
execute a set of standardized validation rules on each of the data elements located at the edge node at the data lake;
store each of the labeled, converted and validated data elements at one or more locations the data lake based on the first schema configuration file; and
archive each of the labeled, converted and validated data elements at the data lake; and
a data chef, operating on the processor coupled to the memory, said data chef operable to:
execute a second schema configuration file on each of the stored data elements, said second schema configuration file operable to transform each of the data elements into integrated, conformed data elements, said second schema configuration file being received from a location other than the data source location, wherein the data elements on which were executed the second schema configuration file qualifies for a first level of curated data; and
execute one or more recipes on each of the stored data elements, the one or more recipes manipulating each of the data elements into consumable data elements that are specifically consumable by one or more end users, the one or more recipes being received from one or more end users, wherein the data elements on which were executed the one or more recipes qualifies for a second level of curated data.
|