| CPC G05B 19/4155 (2013.01) [G06N 3/08 (2013.01); G06N 5/02 (2013.01); G05B 2219/42033 (2013.01)] | 26 Claims |
|
1. A computer-implemented method for process modeling and control, comprising:
receiving data comprising process variables for a subject industrial process of a plant, the process variables including an engineering tag and measurements and said receiving being performed by one or more digital processors;
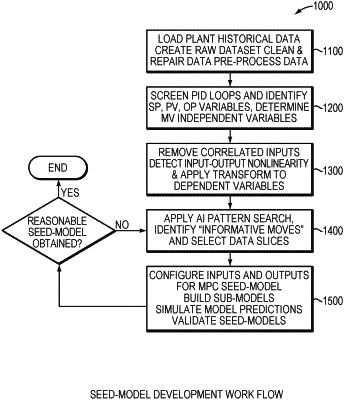
creating, from the received data, a working dataset; the creating being automatically performed by the one or more processors and including:
(i) identifying, based on associations of process variables and calculated statistics, the process variables that comprise PID loops and cascade control loops and associated loop variable types;
(ii) selecting based at least on the identified process variables that comprise PID loops and cascade control loops and associated loop variable types, a first set of process variables as candidate independent variables and a second set of process variables as candidate dependent variables of an empty model of the subject industrial process, the empty model having undefined independent and dependent variables and undetermined model input-output configurations;
(iii) searching the measurements of the first set of process variables in the received data to identify informative moves, based on a magnitude of the change in value of the measurements, for each of the selected candidate independent variables; and
(iv) generating data slices of the received data corresponding to each of the candidate independent variables and at least one of the candidate dependent variables based on the identified informative moves in the measurements of the first set of process variables;
the working dataset being formed of and storing the generated data slices;
building sub-models for the subject industrial process using the generated data slices stored in the working dataset, the sub-models having various model input-output configurations for the selected candidate independent variables and the selected candidate dependent variables and the building being implemented by the one or more processors;
assembling the sub-models in a manner to complete the empty model and producing a seed model of the subject industrial process, the produced seed model utilizing the candidate independent variables and candidate dependent variables of the assembled sub-models as independent variables and dependent variables and utilizing the model input-output configurations of the assembled sub-models as model input-output configurations, said assembling being automatically performed by the one or more processors; and
controlling the subject industrial process at the plant based on the produced seed model.
|