| CPC G10L 17/00 (2013.01) [G06F 3/011 (2013.01); G06T 19/006 (2013.01); G06V 40/161 (2022.01); G10L 25/63 (2013.01); H04R 1/406 (2013.01); H04R 3/005 (2013.01)] | 20 Claims |
|
1. A system comprising:
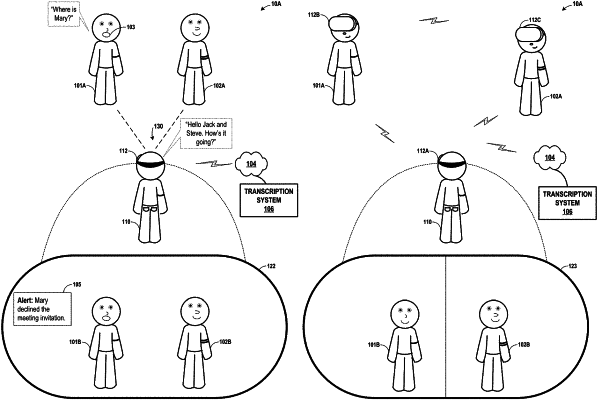
an audio capture system configured to capture audio data associated with a plurality of speakers;
an image capture system configured to capture images of one or more of the plurality of speakers; and
a speech processing engine configured to:
recognize a plurality of speech segments in the audio data,
identify, for each speech segment of the plurality of speech segments and based on the images, a speaker associated with the speech segment,
transcribe each of the plurality of speech segments to produce a transcription of the plurality of speech segments including, for each speech segment in the plurality of speech segments, an indication of which speaker is associated with the speech segment, and
analyze the transcription to identify an instance in which one of the speakers asks another one of the speakers to perform a task, and based on the identified instance, generate a list of tasks.
|