| CPC G10L 15/1815 (2013.01) [G10L 15/063 (2013.01); G10L 15/1822 (2013.01)] | 24 Claims |
|
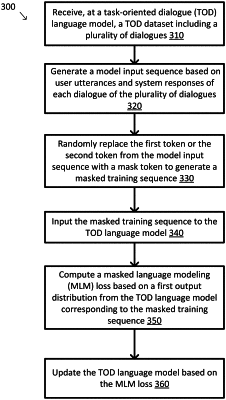
1. A method, comprising:
receiving, at a task-oriented dialogue (TOD) language model, a TOD dataset including a plurality of dialogues, each dialogue of the plurality of dialogues including a plurality of user utterances and a plurality of system responses;
generating a model input sequence by:
prefixing a first token to each user utterance of the plurality of user utterances and a second token to each system response of the plurality of system responses, and
concatenating each of the prefixed user utterances and each of the prefixed system responses;
randomly replacing the first token or the second token from the model input sequence with a mask token to generate a masked training sequence;
inputting the masked training sequence to the TOD language model;
computing a masked language modeling (MLM) loss based on a first output distribution from the TOD language model corresponding to the masked training sequence;
splitting each dialogue from the plurality of dialogues at a respective random turn into a context of the respective dialogue and a response of the respective dialogue;
encoding, by the TOD language model, respective contexts and respective responses corresponding to the plurality of dialogues into a context matrix and a response matrix, respectively;
computing a response contrastive loss (RCL) based on the context matrix and the response matrix generated from the plurality of dialogues; and
updating the TOD language model based on a combination of the MLM loss and the RCL.
|