| CPC G10L 15/063 (2013.01) [G10L 15/02 (2013.01); G10L 15/16 (2013.01); G10L 15/197 (2013.01); G10L 15/22 (2013.01)] | 13 Claims |
|
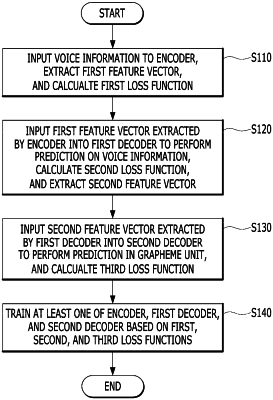
1. A method for speech recognition performed by a computing device, the method comprising:
inputting voice information into an encoder to extract a first feature vector and calculating a first loss function;
inputting the first feature vector extracted from the encoder to a first decoder to perform prediction on the voice information, calculating a second loss function, and extracting a second feature vector;
inputting the second feature vector extracted from the first decoder to a second decoder to perform grapheme-based prediction, and calculating a third loss function;
calculating a final loss function based on the first loss function, the second loss function, and the third loss function; and
training at least one of the encoder, the first decoder, or the second decoder to decease the calculated final loss function.
|