| CPC G10L 15/063 (2013.01) [G06N 3/049 (2013.01); G10L 15/16 (2013.01); G10L 15/187 (2013.01); G10L 15/1815 (2013.01)] | 20 Claims |
|
1. A computer-implemented method that when executed on data processing hardware causes the data processing to perform operations comprising:
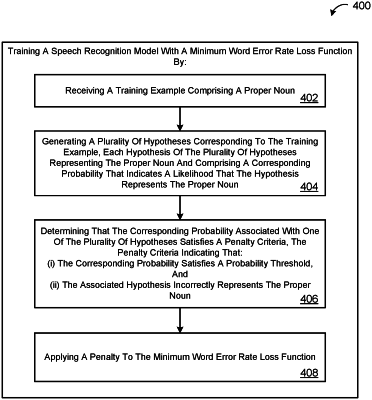
training a speech recognition model with a minimum word error rate loss function by:
receiving a training example comprising a ground-truth transcription, the ground-truth transcription comprising a word sequence that includes a proper noun;
generating a plurality of hypotheses corresponding to the training example, each hypothesis of the plurality of hypotheses comprising a respective sequence of words and a corresponding probability that indicates a likelihood that the hypothesis correctly identifies the ground-truth transcription;
determining that the corresponding probability associated with one of the plurality of hypotheses satisfies a penalty criteria, the penalty criteria indicating that:
the corresponding probability exceeds a value assigned to a probability threshold; and
the respective sequence of words of the associated hypothesis does not include the proper noun; and
applying a penalty to the minimum word error rate loss function based on the corresponding probability associated with the one of the plurality of hypotheses satisfying the penalty criteria.
|