| CPC G10L 15/01 (2013.01) [G10L 15/02 (2013.01); G10L 2015/025 (2013.01)] | 20 Claims |
|
1. A method for evaluating a speech forced alignment model applied in speech synthesis, the method comprising:
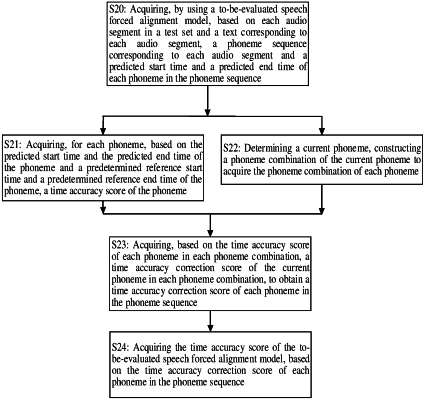
acquiring, by a processor using a to-be-evaluated speech forced alignment model applied in speech synthesis, based on each audio segment in a test set and a text corresponding to each of the audio segments, a phoneme sequence corresponding to each of the audio segments and a predicted start time and a predicted end time of each phoneme in the phoneme sequence;
acquiring, for each phoneme, by the processor, based on the predicted start time and the predicted end time of the phoneme and a predetermined reference start time and a predetermined reference end time of the phoneme, a time accuracy score of the phoneme, wherein the time accuracy score is a degree of proximity of the predicted start time and the predicted end time of each of the phonemes to the reference start time and the reference end time corresponding to the predicted start time and the predicted end time; and
acquiring, by the processor, based on the time accuracy score of each of the phonemes, a time accuracy score of the to-be-evaluated speech forced alignment model, wherein the to-be-evaluated speech forced alignment model includes a GMM model (Gaussian mixture model) and a Viterbi decoding model, wherein each audio segment in the test set and the text corresponding to each audio segment is input into the GMM model to obtain an undecoded phoneme sequence, the predicted start time and the predicted end time; and
decoding the undecoded phoneme sequence by the Viterbi decoding model to obtain the decoded phoneme sequence and the predicted start time and the predicted end time.
|