| CPC G06V 20/46 (2022.01) [G06F 16/73 (2019.01); G06F 16/78 (2019.01); G06F 18/214 (2023.01); G06F 18/22 (2023.01); G06N 5/04 (2013.01); G06N 20/00 (2019.01); G06V 10/751 (2022.01); G06V 20/49 (2022.01); G11B 27/036 (2013.01); G11B 27/34 (2013.01); H04N 5/147 (2013.01)] | 20 Claims |
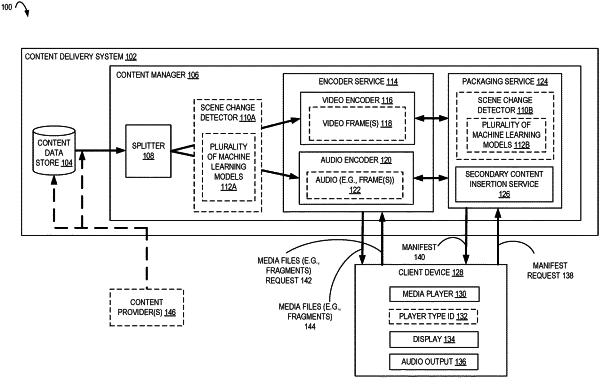
|
1. A computer-implemented method comprising:
receiving a request to train a plurality of machine learning models comprising a query model, a key model, and a temporal model, on a training dataset of videos without labels that indicate scene changes in a first set of shots and having labels that indicate scene changes in a second set of shots, to detect a video scene change;
extracting features of a query shot, and neighboring shots of the query shot, of the first set of shots without labels with the query model;
determining a key shot of the neighboring shots which is most similar to the query shot based at least in part on the features of the query shot and the neighboring shots;
extracting features of the key shot with the key model;
training the query model of the plurality of machine learning models into a trained query model based at least in part on a comparison of the features of the query shot and the features of the key shot;
extracting features of the second set of shots with labels with the trained query model;
training the temporal model of the plurality of machine learning models into a trained temporal model based at least in part on the features extracted from the second set of shots and the labels of the second set of shots;
receiving an inference request for an input video;
partitioning the input video into a plurality of shots;
generating, by the plurality of machine learning models, an inference of one or more scene changes in the input video based at least in part on the plurality of shots of the input video; and
transmitting the inference to a client application or to a storage location.
|