| CPC G06Q 10/06315 (2013.01) [G06N 5/04 (2013.01); G06N 20/00 (2019.01); G06Q 10/0875 (2013.01); G06Q 40/08 (2013.01); G06V 20/50 (2022.01); G06F 3/0484 (2013.01); G06F 3/04815 (2013.01)] | 20 Claims |
|
1. A tangible, non-transitory, machine-readable medium, comprising machine-readable instructions, that when executed by one or more processors, cause the one or more processors to:
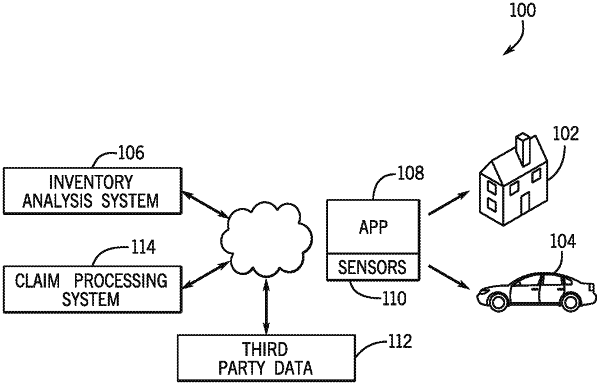
receive, from a camera system, a pre-event capture of an environment;
generate a three-dimensional (3D) model of the environment based upon the pre-event capture, wherein generating the 3D model comprises identifying control software associated with an Internet of Things (IoT) device and associating a function of the control software with the 3D model to enable operation of the function via virtual interaction with the 3D model;
identify, using machine learning, items in the pre-event capture, wherein the operation of the function of the control software facilitates detection of at least a portion of pre-event information associated with one or more items of the items in the pre-event capture;
generate an inventory list, by accumulating the items and associated pre-event information from the pre-event capture;
apply the inventory list to the 3D model;
present the 3D model with selectable item indicators for each of the items in the inventory list;
upon selection of one of the selectable item indicators associated with an item, present a graphical dialog box with respective pre-event information associated with the item;
receive, from the camera system, a post-event capture of the environment;
identify, using machine learning, items in the post-event capture and receive post-event information associated with each item identified in the post-event capture;
compare the items and the associated pre-event information in the inventory list with the items and the associated post-event information in the post-event capture to determine a portion of the items in the inventory list that are damaged or missing;
generate a comparison report based upon comparing the items in the inventory list with the items in the post-event capture; and
predict a loss estimate based upon the comparison report.
|