| CPC G06N 20/00 (2019.01) [G06F 9/38 (2013.01); G06F 18/217 (2023.01); G06F 18/2178 (2023.01); G06F 18/23 (2023.01); G06F 18/285 (2023.01); G06N 5/04 (2013.01)] | 20 Claims |
|
1. A method comprising:
receiving, by at least one processor from a user computing device, an objective to be analyzed using a model trained with machine learning;
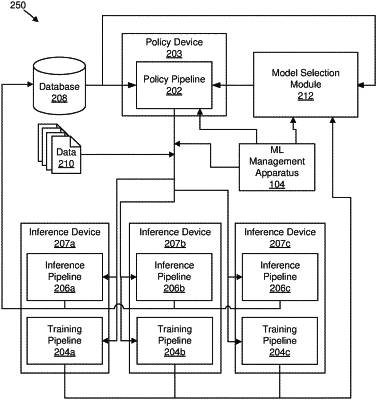
identifying, by the at least one processor, a grouping of pipelines for analyzing the objective, the grouping of pipelines comprising:
a training pipeline comprising first code configured to train, using a training dataset associated with the objective, the model to receive an input from the user computing device and analyze the input in accordance with the training pipeline;
one or more inference pipelines comprising second code configured to generate, via the model, an outcome corresponding to the input received from the user computing device; and
a policy pipeline comprising third code configured to push the model to the one or more inference pipelines;
selecting, by the at least one processor responsive to the objective, the one or more inference pipelines from the grouping of pipelines for analyzing the objective, wherein the one or more inference pipelines is configured to send, during execution, a message to at least one of the training pipeline or the policy pipeline indicative of an error;
adjusting, by the at least one processor, a setting of the model based on the message sent by the one or more inference pipelines selected to analyze the objective; and
presenting, by the at least one processor, for display on the user computing device, an indication of at least one parameter of at least one pipeline of the one or more inference pipelines.
|