| CPC G06N 7/01 (2023.01) [G06N 5/02 (2013.01); G06Q 10/101 (2013.01); G06Q 30/00 (2013.01); G06Q 30/02 (2013.01); G06Q 50/01 (2013.01)] | 9 Claims |
|
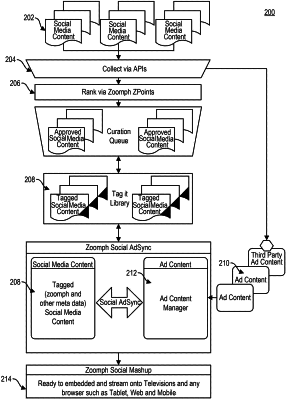
1. A server comprising:
a processor;
a memory device communicatively coupled to the processor; and
wherein the processor is configured to obtain a first plurality of prediction sets by determining a plurality of probability distributions associated with a characteristic of an individual and use a probabilistic classifier to generate a merged probability distribution based on the plurality of probability distributions;
a database communicatively coupled to the processor, configured to store the first plurality of prediction sets, each prediction set being associated with a respective characteristic of an individual within a first population, each prediction set comprising a plurality of prediction results, each prediction result corresponding to a selected one of a plurality of features associated with the characteristic; and
wherein the processor is configured to
generate a plurality of distribution values associated with the selected one feature by determining, for each respective prediction result, a respective distribution value for the selected one feature based on the respective plurality of corresponding prediction results in a respective prediction result group;
determine an average distribution value based on the plurality of distribution values, the average distribution value indicating how often the selected feature appears as a characteristic in a second population of individuals;
select an advertisement image based on the average distribution value; and
display the advertisement image on a first display in a particular location among a plurality of displays in various locations, wherein the first display is selected for the advertisement image based on a percentage distribution of a prediction result associated with the selected one of the plurality of features, among the plurality of prediction results, predicted to be present among the characteristics of the individuals in the particular location.
|