| CPC G06N 3/063 (2013.01) [G06F 1/3287 (2013.01); G06F 1/3293 (2013.01); G06F 9/30014 (2013.01); G06F 9/30036 (2013.01); G06F 15/76 (2013.01); G06F 15/78 (2013.01); G06N 3/04 (2013.01); G06N 3/044 (2023.01); G06N 3/045 (2023.01); G06N 3/08 (2013.01); G06N 3/084 (2013.01); G06T 1/20 (2013.01); G06T 15/005 (2013.01); G06T 1/60 (2013.01)] | 17 Claims |
|
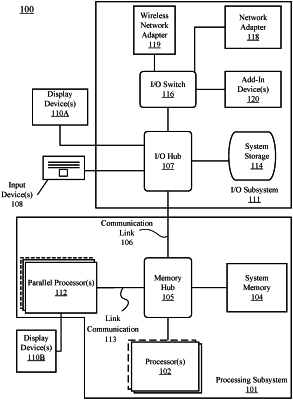
1. An apparatus comprising:
at least one processing resource;
at least one field programmable gate array (FPGA) communicatively coupled to the at least one processing resource; and
a processor to:
determine one or more workload requirements for at least one of a workload or an execution thread;
remap the at least one of the workload or the execution thread to the FPGA on a selective basis; and
convert the low compute load operations into bits which become part of a context state of a thread.
|