| CPC G06F 40/30 (2020.01) [G06F 40/284 (2020.01); G06F 40/289 (2020.01); G06N 3/08 (2013.01)] | 11 Claims |
|
1. A processor-implemented method (200) comprising:
receiving (202), via one or more hardware processors, at least one text input having at least one subject and at least one object;
tokenizing (204), via the one or more hardware processors, the received at least one text input using a predefined word delimiter;
tagging (206), via the one or more hardware processors, each word of the tokenized at least one text input based on a part-of-speech (POS) and a universal dependency tag, wherein a universal dependency tag tree is identified from the each tagged word with the universal dependency tag;
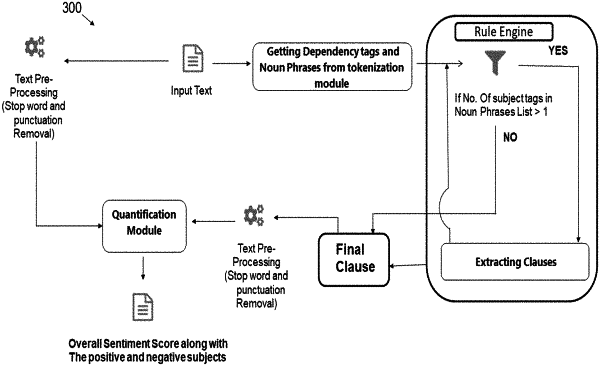
identifying (208), via the one or more hardware processors, at least one subject and at least one object from the tagged each word of the at least one text input using a subject-verb-object (SVO) detection model, wherein the identified at least one subject and the at least one object is classified in noun chunks;
analyzing, via the one or more hardware processors, the noun chunks to identify a number of subjects and a number of objects in the at least one text input, wherein a first subject word of the at least one text input is marked with a subject tag when the number of subjects is more than one and a first object word is marked with an object tag, and wherein, if in the at least one text input the first object word is followed with a word having an object, then the first object word with the object tag is changed with the following word as an object tag of the at least one text input;
analyzing (210), via the one or more hardware processors, the universal dependency tag tree for the identified at least one subject to determine a token dependency of the identified at least one subject using a predefined list of tuples of each word and a universal dependence tag of each tuple using a dependency parser, wherein at least one phrase is extracted corresponding to the identified at least one subject from the determined token dependency and the extracted at least one phrase is represented in a numerical vector, and wherein the dependency parser analyzes a grammatical structure of the at least one text input, establishing a relationship between a headword and a word, which modify the headword and the dependency parser supports a universal dependency scheme where the universal dependency is a framework for a consistent annotation of grammar across different languages, and varied dependency tags are present describing relationship of each word with neighboring words, wherein after getting dependency tags and noun phrases from the input text, a rule engine is calibrated to use the dependency tags and the noun phrases to extract clauses relevant to the identified at least one subject;
quantifying (212), via the one or more hardware processors, the identified at least one subject using a pre-trained deep learning-based sentiment analyzer and a predefined class score of the at least one subject, wherein a probability score is obtained against the identified at least one subject, wherein the deep learning-based sentiment analyzer is pre-trained on a dataset using a convolutional neural network (CNN) model and one or more noun phrases of each subject are converted to word embedding and are given to the pre-trained deep learning-based sentiment analyzer for sentiment determination, wherein sentiment of the each subject in the at least one text input is quantified separately and an overall sentiment of the at least one text input is quantified, wherein the sentiment is quantitatively measured at a subject level along with at a text input level, wherein input to the CNN model is the extracted at least one phrase corresponding to the identified at least one subject and output of the CNN model is a list of probability scores for each sentiment class, wherein the CNN model comprises an input layer, an embedding layer, a plurality of convolution layers, a pooling layer and a dense layer, wherein the input layer takes a sequence of tokens of the received at least one text input as input to the CNN model, wherein the embedding layer is a look-up table, wherein each tokenized word of the received at least one text input is mapped to a trainable feature vector, wherein the plurality of convolution layers comprises of a set of independent learnable filters and each of the learnable filters is independently convolved with an embedding matrix producing different feature maps, and wherein the pooling layer operates on each feature map independently;
calculating a sentiment score of to the quantified subject using an equation:
 wherein Si is the predefined class score ranging from −1.0 to 1.0 and Pi is the probability score given by the CNN model at an output layer, and wherein the sentiment score is computed for the clause and the sentiment score calculation is repeated for subsequent clause extracted corresponding to the identified at least one subject and once the sentiment score for each phrase is quantified, the corresponding subject of each phrase is classified as a positive subject or a negative subject of the at least one text input; and
recommending (214), via the one or more hardware processors, the sentiment score to the quantified subject along with a sentiment score to the received text input based on the quantified at least one subject and the probability score of the identified at least one subject.
|