| CPC G06F 40/30 (2020.01) [G06F 40/216 (2020.01)] | 10 Claims |
|
1. A method for training a machine-learning model used to provide recommendations for costumes for characters within a dynamic visual media, the method comprising:
receiving a dynamic visual media script for recommendation of at least one costume;
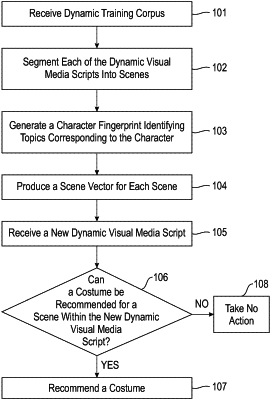
accessing, at an information handling device, a dynamic visual media corpus, wherein the dynamic visual media corpus comprises a plurality of dynamic visual media scripts;
segmenting each of the plurality of dynamic visual media scripts into scenes, wherein the segmenting comprises identifying, utilizing at least one scene segmentation technique to enclose semantic boundaries, a segment by identifying a portion of the dynamic visual media script having a costume and corresponding context that are consistent throughout the portion;
generating, for each of the plurality of dynamic visual media scripts, a character fingerprint identifying topics corresponding to each character within a corresponding dynamic visual media script, wherein the generating comprises (i) extracting both characters and topics from the dynamic visual media script and (ii) associating each of the topics with a corresponding character and comprises generating a topic-relationship graph across the dynamic visual media corpus, wherein the topic-relationship graph represents topics occurring within the plurality of dynamic visual media scripts as nodes and relationships between the topics as edges, wherein the edges are weighted with an occurrence frequency, wherein the character fingerprint identifies costumes of a given character and a topic corresponding to each costume;
producing, for each scene within each dynamic visual media script, a scene vector identifying (iii) the topics included within a corresponding scene and (iv) a character fingerprint for each character occurring within the scene and training the machine-learning model with the scene vectors;
encoding, within each scene within each dynamic visual media script, a topic encoding vector using the topic-relationship graph, the character fingerprint, and the scene vector, wherein the topic encoding vector reflects an overall story of the dynamic visual media script and ensures consistency of costume generation of a character throughout the dynamic visual media script; and
providing, based upon the topic encoding vectors, at least one recommendation for a costume within the received dynamical visual script, wherein the providing at least one recommendation comprises applying a generative adversarial network to each scene vector of the received dynamic visual script against the scene vectors of the machine-learning model, thereby generating one or more costumes for the dynamic visual media scene of the received dynamic visual media script.
|