| CPC G06F 40/284 (2020.01) [G06F 40/211 (2020.01); G06F 40/30 (2020.01); G06N 3/08 (2013.01)] | 20 Claims |
|
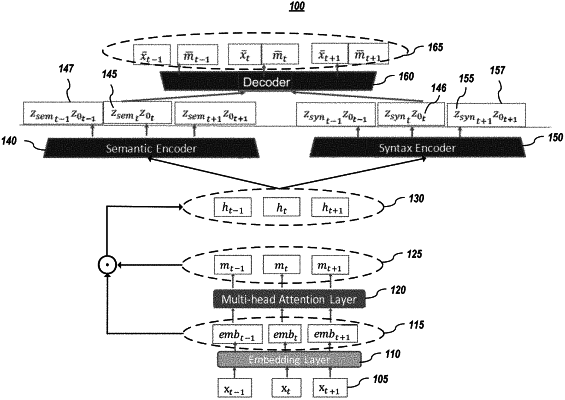
1. A computer-implemented method for segmenting latent representations comprising:
given a variational autoencoder (VAE) model comprising an attention layer, a semantic encoder, a syntax encoder, and a decoder:
generating, using an embedding layer, a sequence of embeddings for a sequence of tokens, in which the tokens are words or representations of words;
generating, using the attention layer, a sequence of attention masks based on the sequence of embeddings;
generating a sequence of hidden variables based on the sequence of embeddings and the sequence of attention masks;
generating, using the semantic encoder, a first sequence of latent variables based on the sequence of hidden variables;
generating, using the syntax encoder, a second sequence of latent variables based on the sequence of hidden variables;
inferring, using the decoder, a sequence of reconstructed tokens and a sequence of reconstructed attention masks using at least information of the first sequence of latent variables from the semantic encoder and the second sequence of latent variables from the syntax encoder; and
using the sequence of reconstructed tokens and the sequence of reconstructed attention masks to train at least the attention layer, the semantic encoder, the syntax encoder, and the decoder of the VAE model.
|