| CPC G06F 40/284 (2020.01) [G10L 25/30 (2013.01); G16H 10/60 (2018.01)] | 18 Claims |
|
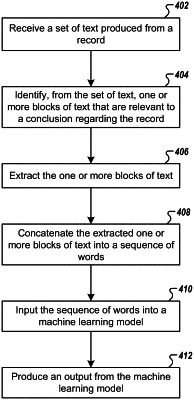
1. A method for automatically auditing medical records, the method comprising:
receiving a set of text produced from a medical record, the set of text comprising non-repeating text;
selecting a text identification methodology from a plurality of different text identification methodologies based on historical effectiveness, the plurality of different text identification methodologies comprising an embedding layer;
identifying, by block manipulation circuitry that uses the selected text identification methodology and from the set of text, one or more blocks of text that are related to a medical diagnosis, the one or more blocks of text consisting essentially of a proper subset of the non-repeating text;
extracting, by the block manipulation circuitry, the one or more blocks of text;
concatenating, by the block manipulation circuitry, the extracted one or more blocks into a sequence of words;
inputting the sequence of words into a machine learning model; and
in response to inputting the sequence of words into the machine learning model, producing, using the machine learning model, an indication of whether an ICD code associated with the medical record is supported by the sequence of words;
wherein identifying the one or more blocks of the set of text that are related to a medical diagnosis comprises:
applying, by the block manipulation circuitry, the embedding layer to the set of text to identify the one or more blocks;
wherein applying the embedding layer to the set of text to identify the one or more blocks comprises:
inputting the set of text into a Word2Vec model to vectorize each block in the set of text;
inputting each ICD code description into the Word2Vec model to vectorize each ICD code description;
applying, by the block manipulation circuitry, a cosine similarity function to identify, as a high importance block, each block in the set of text whose vectorization is similar to a vectorization of an ICD code description; and
identifying, by the block manipulation circuitry, the high importance blocks of text as the one or more blocks.
|