| CPC G06F 16/285 (2019.01) [G06F 16/2358 (2019.01); G06F 16/2457 (2019.01); G06F 16/2468 (2019.01)] | 15 Claims |
|
1. A method for managing source identifiers of transaction records, comprising:
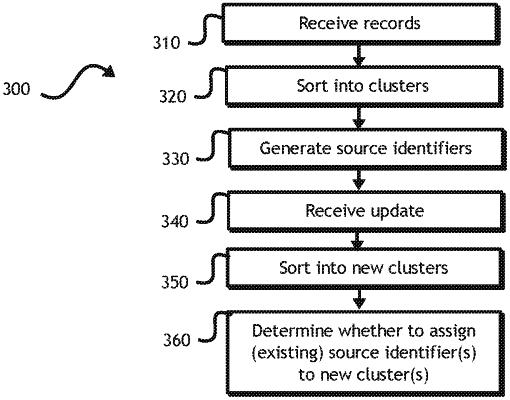
receiving, with at least one processor, a plurality of transaction records, each respective transaction record of the plurality of transaction records comprising identification data associated with a source of the respective transaction record, the source for each respective transaction record of the plurality of transaction records comprising a respective merchant, the identification data for each respective transaction record of the plurality of transaction records comprising a respective name and address key pair associated with the respective merchant;
sorting, with the at least one processor, the plurality of transaction records into a first plurality of clusters based on the identification data, each cluster of the first plurality of clusters including at least one transaction record of the plurality of transaction records;
generating, with the at least one processor, a first source identifier for each respective cluster of the first plurality of clusters based on the respective name and address key pair of respective transaction records of the plurality of transaction records sorted into the respective cluster;
receiving, with the at least one processor, update data associated with an update to the plurality of transaction records;
sorting, with the at least one processor, at least some of the plurality of transaction records into a second plurality of clusters based on the identification data and the update data, wherein a first new cluster of the second plurality of clusters has first new identification data different from the identification data associated with an existing cluster of the first plurality of clusters and a second new cluster of the second plurality of clusters has second new identification data that substantially matches the identification data associated with the existing cluster of the first plurality of clusters, wherein substantially matching comprises at least one of exactly matching, matching within a predetermined tolerance, matching based on fuzzy matching, or matching closely enough to have been sorted into a same cluster; and
determining, with the at least one processor, to assign the first source identifier of the existing cluster of the first plurality of clusters to the second new cluster of the second plurality of clusters based on at least one of a number of transacting records of the existing cluster, a number of non-transacting records of the existing cluster, a number of transacting records of the first new cluster, a number of non-transacting records of the first new cluster, a number of transacting records of the second new cluster, or a number of non-transacting records of the second new cluster.
|