| CPC G06F 16/1744 (2019.01) [G06F 16/137 (2019.01); H03M 7/3064 (2013.01)] | 13 Claims |
|
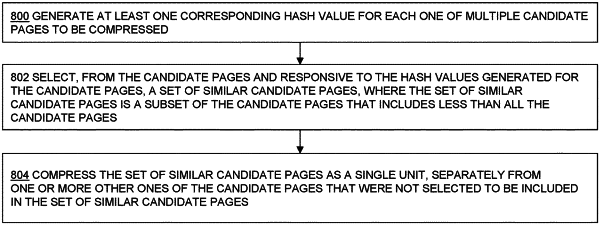
1. A method comprising:
generating a corresponding set of hash values for each one of a plurality of candidate pages to be compressed;
selecting, from the candidate pages and responsive to the sets of hash values generated for the candidate pages, a set of similar candidate pages, wherein the set of similar candidate pages comprises a subset of the candidate pages that includes less than all the candidate pages, at least in part by:
comparing the sets of hash values corresponding to the candidate pages at least in part by generating, for each pair of candidate pages, a similarity index using the sets of hash values corresponding to that pair of candidate pages,
identifying a set of candidate pages within which each candidate page has a corresponding set of hash values with at least a minimum similarity index value with respect to the corresponding set of hash values of each other candidate page, and
selecting the set of candidate pages with corresponding sets of hash values having at least the minimum threshold level of similarity to each other as the set of similar candidate pages; and
compressing the set of similar candidate pages as a single unit, and separately from one or more other ones of the candidate pages that were not selected to be included in the set of similar candidate pages.
|